Data 360 の RAG 関連 用語集
公開日 : 2025.07.29
Share:



2025 年 10 月 14 日以降、Data Cloud は Data 360 にブランド変更されました。
はじめに
Data 360 で RAG を活用するためには、関連する一般用語や Salesforce に関連する用語の定義を理解する必要があります。この記事では、これらの用語をカテゴリ別に解説します。
AI の概念・アーキテクチャ
大規模言語モデル( LLM - Large Language Model )
大規模言語モデル( LLM )とは、膨大な量のテキストデータを学習し、人間のように自然な文章を生成したり、要約したり、質問に答えたりする能力を持つ AI モデルです。 Chat GPT の GPT-4 などがその代表例であり、生成 AI の頭脳として機能します。 Salesforce プラットフォームにおいても、生成 AI 機能が応答を生成する過程などで大規模言語モデルが使用されています。
プロンプト( Prompt )
LLM に対して指示や質問を与えるための入力文のことです。 LLM はこのプロンプトに基づいて文章や画像などを生成します。適切なプロンプトを設計することで、望ましい出力結果を得ることができます。プロンプトは、自然言語で LLM に指示を与えられるという手軽さから使いやすい一方で、その内容によって出力品質が大きく左右されるため、生成 AI 活用において極めて重要な要素です。
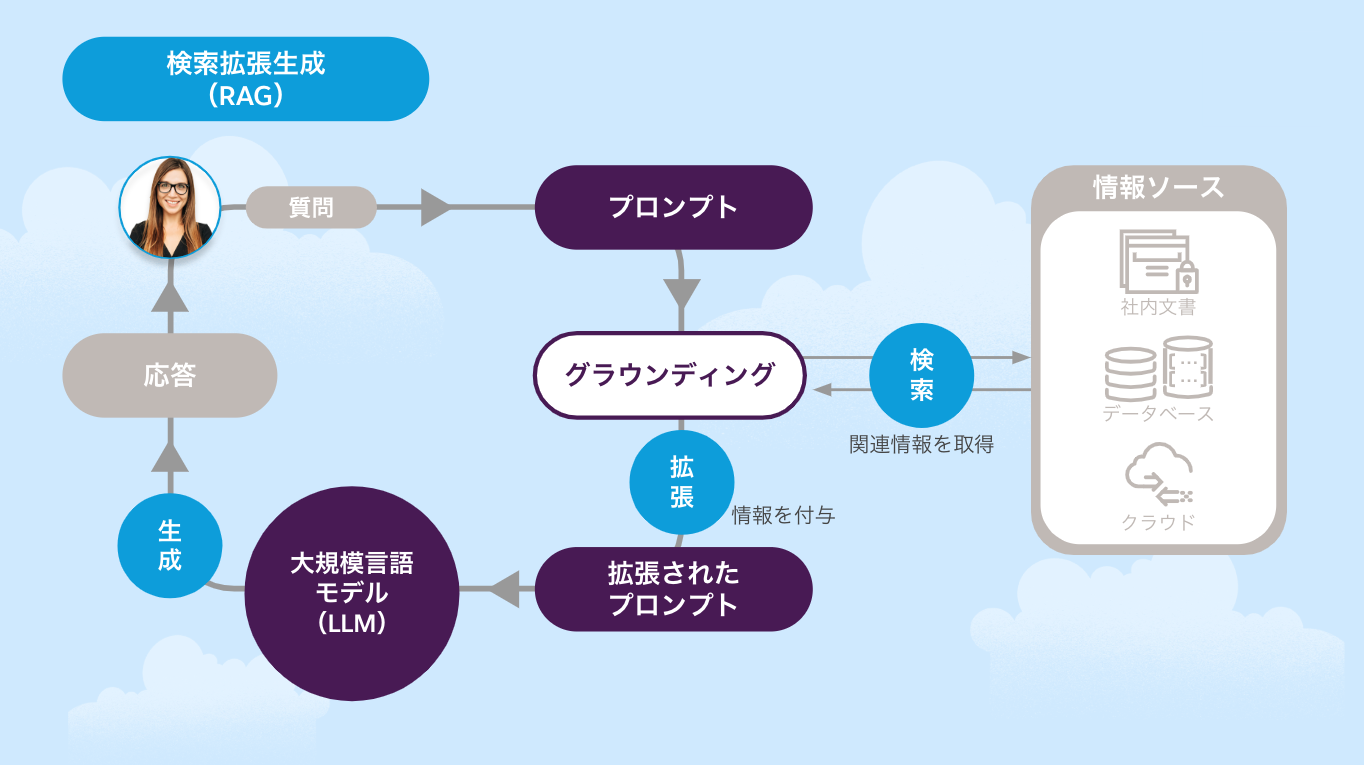
グラウンディング( Grounding )
グラウンディング( Grounding )とは、 LLM のような生成 AI が単なる学習データに依存するだけではなく、顧客情報などのデータに基づいた文脈をプロンプトに付与するためのプロセスを指します。 LLM が事実に基づかない、もっともらしい「嘘」を生成してしまう「ハルシネーション」を防ぐために極めて重要なプロセスです。
検索拡張生成( RAG - Retrieval-Augmented Generation )
検索拡張生成( RAG )とは、 LLM が回答を生成する際に、指定した特定の情報ソースから関連情報を検索し、その情報をグラウンディングに利用する技術です。これにより、 LLM が持つ一般的な知識と、企業固有の最新かつ正確なデータを組み合わせることが可能になります。 Data 360 の文脈において、 RAG は Agentforce が顧客データやナレッジ記事などの情報を基に、文脈に沿った正確な回答を生成するためのコア技術として機能します。
データの種類
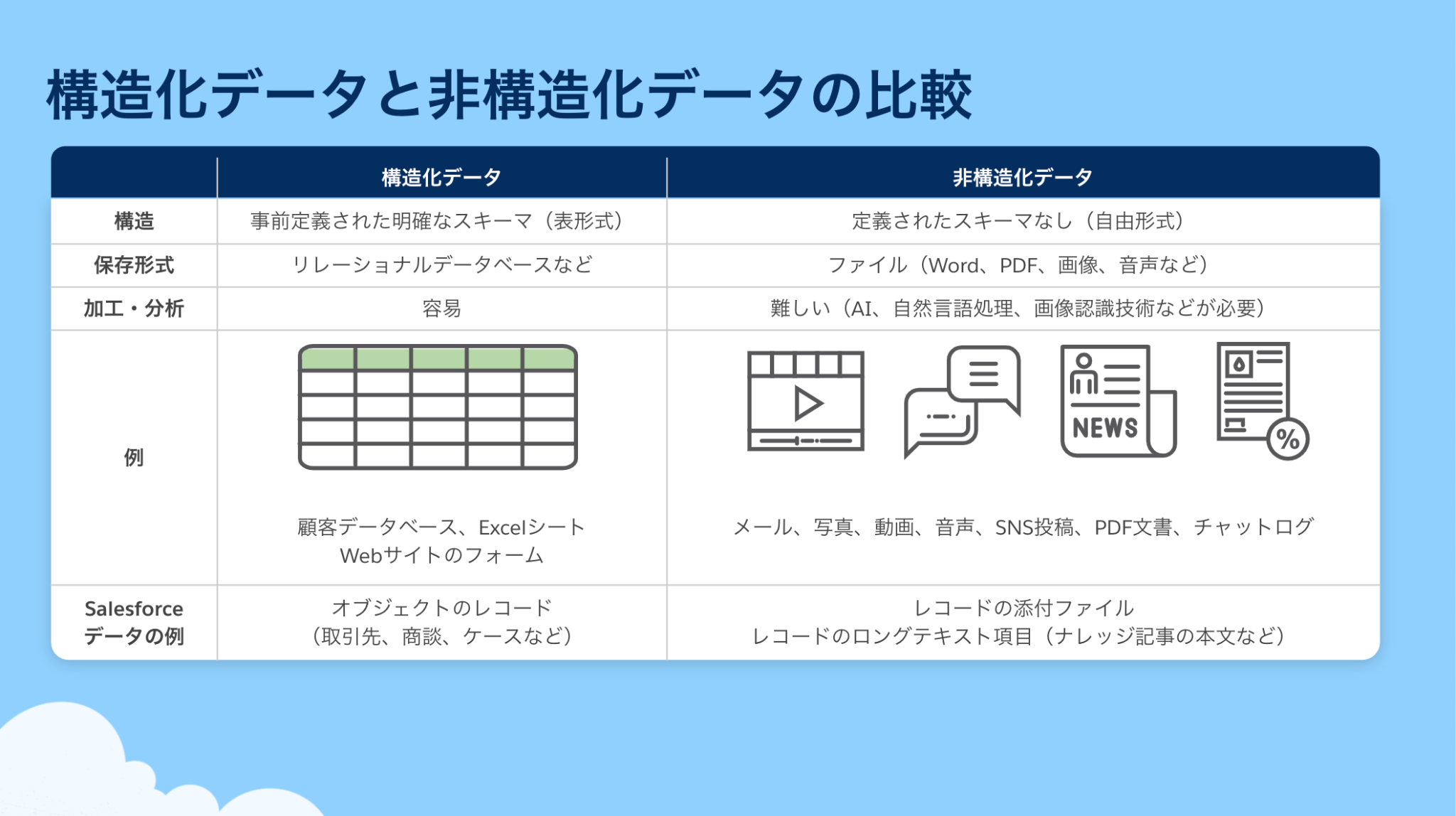
構造化データ
Salesforce オブジェクトのレコードや Excel のデータ行のように、事前に定義された形式や固定された項目に整理されているデータです。
非構造化データ
事前に定義された形式や構造を持たないデータ。テキスト文書や音声・動画ファイル、画像、ソーシャルメディアの投稿などが非構造化データにあたります。 RAG の観点では、 LLM がより正確で具体的かつ状況に応じた回答を生成するための「グラウンディング」に不可欠です。
データ処理・検索技術
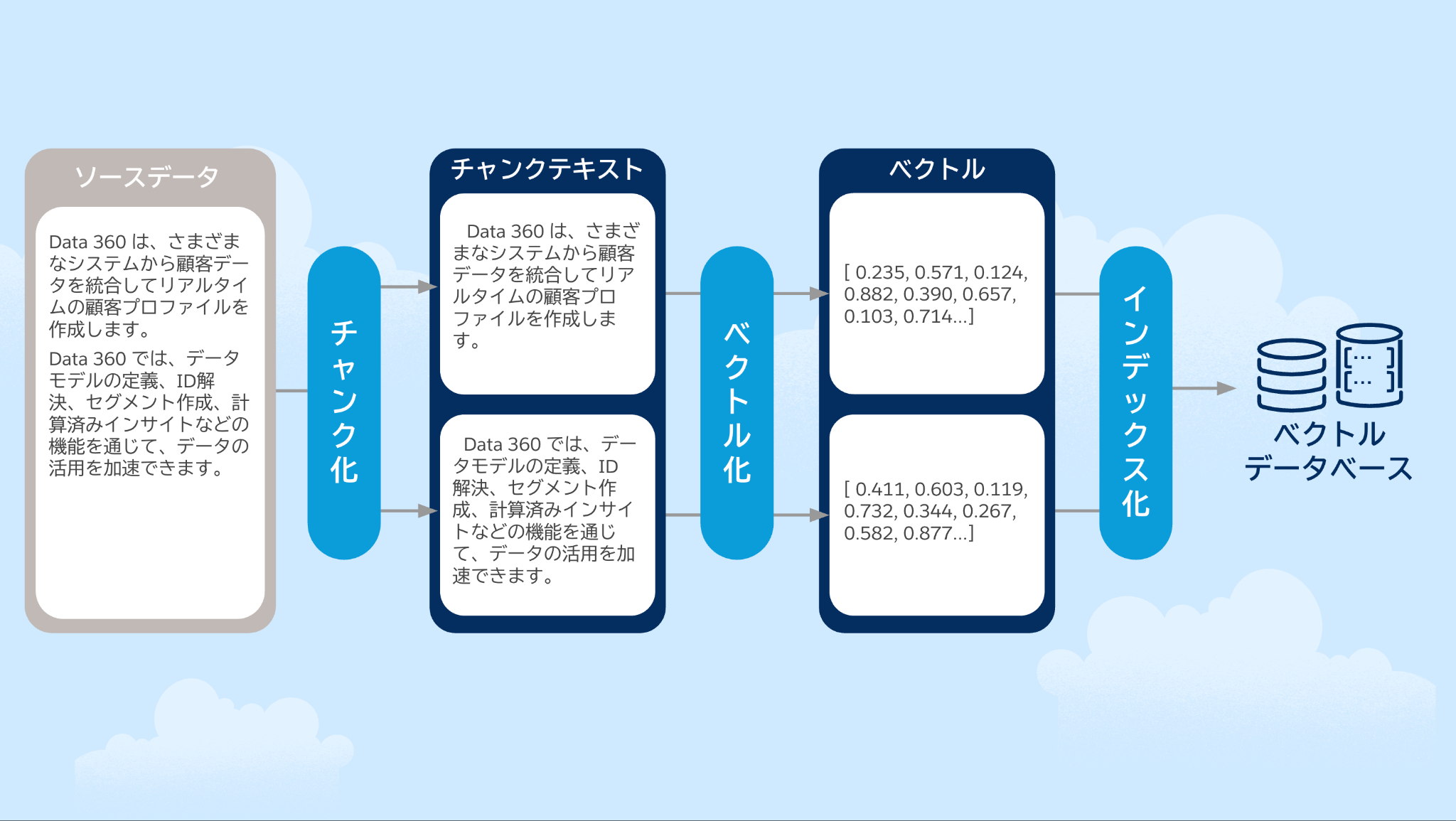
チャンク化( Chunking )
チャンク化とは、長いドキュメントやテキストを、 AI が処理しやすいように、意味のある小さな塊(チャンク)に分割するプロセスです。一度に扱える情報量には限りがある LLM に対して、長文の中から最も関連性の高い部分だけを効率的に提供するために不可欠な前処理です。 Data 360 の文脈では、例えば長いナレッジ記事や規約文書などをインデックス化する際に、このチャンク化が行われます。適切に分割されたチャンクテキストにより、ユーザーの質問に対して、文書全体ではなく、最も的確な一部分をピンポイントで検索結果として提示できるようになり、 RAG の精度が向上します。
ベクトル化( Vector Embeddings )
ベクトル化とは、テキストや画像などのデータを、 AI が意味の近さを計算できるような数値の配列(ベクトル)に変換するプロセスです。例えば、「ノートパソコン」と「ラップトップ」は異なる単語ですが、ベクトル化すると空間上で非常に近い位置に配置され、意味的に類似していると判断されます。 Data 360 では、ナレッジ記事、ケースのやり取り、商品情報といった非構造化データからチャンク化されたテキストがベクトル化され、データベースに格納されます。これにより、キーワードの一致だけではない、意味の類似性による検索を行えます。
インデックス化( Indexing )
データ(特にチャンク化されたデータ)をベクトルデータベースやキーワードインデックスなどのデータベース内で整理し、検索可能な構造として保存するプロセスを指します。大量のデータから最も関連性の高い情報を効率的かつ正確に検索するために不可欠な基盤を構築します。適切にインデックス化されたデータは、 RAG プロセスにおいて LLM (大規模言語モデル)に提供されるコンテキスト(文脈)の質を向上させます。
ベクトルデータベース( Vector Database )
ベクトルデータベースとは、ベクトルデータの格納、管理、そして高速な類似性検索(ベクトル検索)に最適化されたデータベースです。従来のデータベースが構造化データの管理やキーワード検索を得意とするのに対し、ベクトルデータベースは意味の近さに基づいた検索を効率的に実行できます。 Data 360 は、このベクトルデータベース機能をプラットフォームにネイティブで内包しています。これにより、ベクトル化された顧客データやナレッジを外部のデータベースに移動させることなく、 Salesforce の堅牢なセキュリティの範囲内で安全に管理・活用できます。
セマンティック検索 / ベクトル検索 ( Semantic Search / Vector Search )
セマンティック検索は、キーワードの一致だけでなく、単語やフレーズの意味を理解し、ユーザーの意図に関連性の高い情報を探し出す検索手法です。このセマンティック検索を技術的に可能にするのがベクトル検索で、ユーザーの質問(プロンプト)をベクトル化し、データベース内のベクトルとの距離を計算することで、関連性の高い情報を見つけ出します。これは RAG における「検索( Retrieval )」を担う非常に重要な部分です。 Salesforce においては、ユーザーが Agentforce に質問をすると、裏側ではこのベクトル検索が実行され、質問の意図に関連性が高い顧客データやナレッジの断片(チャンク)が特定され、応答生成のためのグラウンディングに使用されます。ベクトル検索はセマンティック検索のための主要な「手段」の一つです。
Salesforce に関連する用語
Data 360
Data 360 は、 Salesforce プラットフォームにネイティブに統合されたデータ基盤です。 CRM データ、 Web サイトの行動履歴、基幹システムのデータなど、社内外のあらゆる顧客データをリアルタイムで集約・統合し、顧客一人ひとりの統合プロファイルを構築します。 RAG の文脈において、 Data 360 は最も重要かつ信頼できる「ナレッジベース(知識源)」そのものです。ここに集約・統合された最新かつ正確なデータがグラウンディングの基盤となり、 AI が常に信頼できる情報源から回答を生成できるようになります。
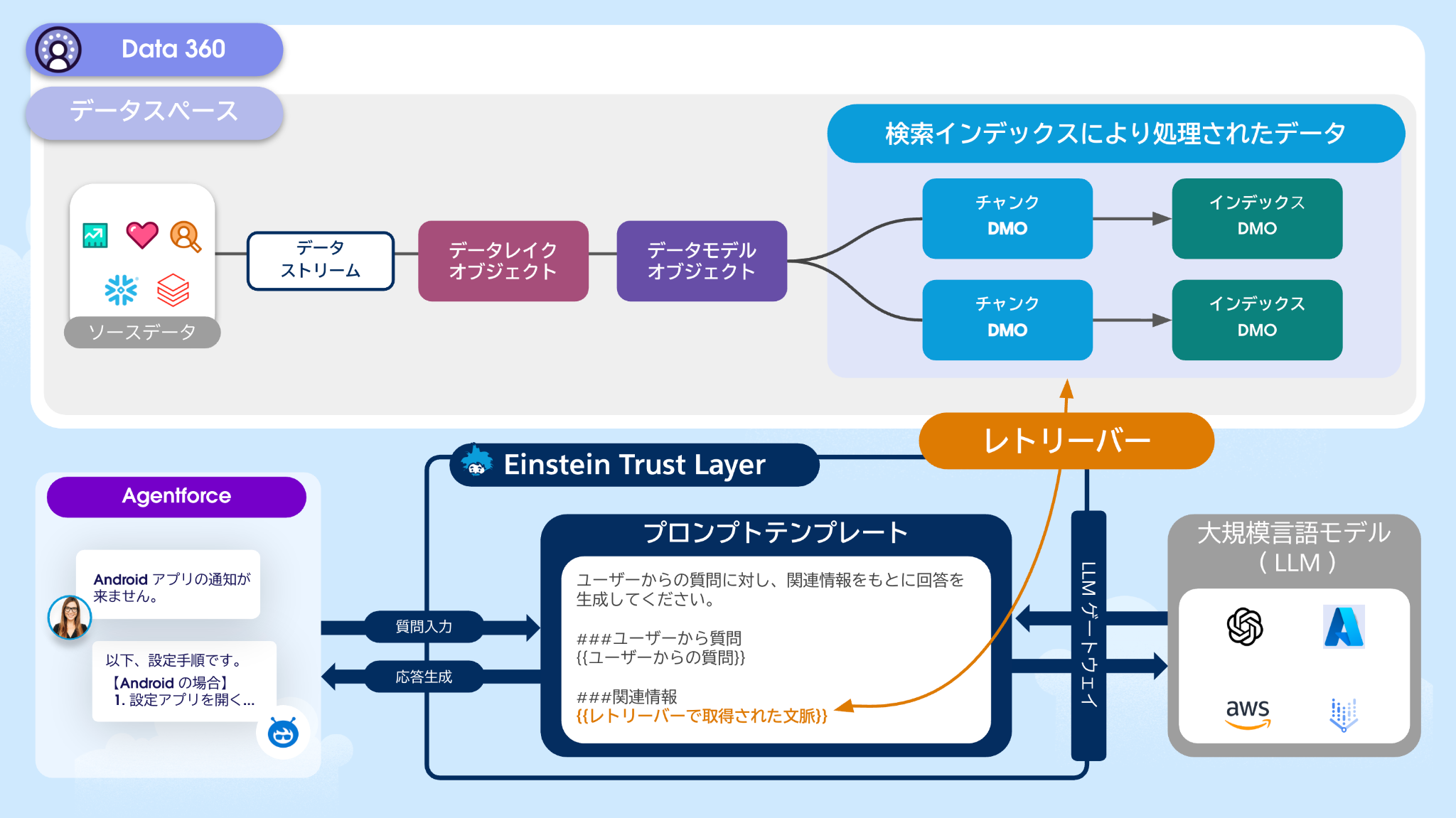
データスペース ( Data Space )
単一の Data 360 環境内に作成される、データを論理的に分割・整理するための「仕切り」のようなもの。これにより、企業はブランド、地域、部門といった単位でデータ、メタデータ、プロセスを分離し、それぞれに応じたアクセス制御やデータ活用を実現できます。
データストリーム( DS : Data Stream )
様々なデータソースから Data 360 にデータを接続し、取り込む機能です。 Data 360 内でデータを取り込み、処理するための入り口となり、取り込み対象データや頻度の制御を行います。
データレイクオブジェクト( DLO : Data Lake Object )
構造化データや非構造化データを取り込み、保存するためのオブジェクトです(データベースでのテーブルに相当)。ローデータや非構造化データの主要な格納場所として機能します。
データモデルオブジェクト( DMO : Data Model Object )
Data 360 内で構造化されたデータや、非構造化データから派生したデータ(チャンクやベクトルなど)を構造化された形式で保存するためのオブジェクトです (データベースでのビューに相当)。データレイクオブジェクトから取り込まれたデータや、直接取り込まれた構造化データを、分析やベクトル検索で利用しやすいように構造化・整理する役割を担います。
検索インデックス( Search Index )
ソースとなる構造化/非構造化データモデルオブジェクトを RAG で検索可能にするための Data 360 の機能。検索インデックスを設定することにより、ソースとなるデータモデルオブジェクトを元にした Chunk DMO ( Data Model Object )と Index DMO ( Data Model Object )が作成されます。 Chunk DMO にはチャンク化されたテキストデータ、 Index DMO にはチャンク化されたテキストをベクトル化したデータが格納されます。
レトリーバー( Retriever )
レトリーバーは、 RAG の中で検索を担う機能です。ユーザーの質問を受け取り、それを基に検索インデックスの中から最も関連性の高い情報(データチャンク)を探し出して取得する役割を担います。ユーザーが Agentforce に質問をすると、レトリーバーがその質問をベクトルに変換し、 Data 360 のベクトルデータベースに対して検索を実行します。そして見つけ出した最適な情報をプロンプトテンプレートに渡し、それが LLM に送信されることで生成結果の精度向上に寄与します。
プロンプトテンプレート(Prompt Template)
プロンプトテンプレートとは、 LLM への指示(プロンプト)を効率的かつ安定的に生成するための雛形です。あらかじめ定義された文章の中に、特定の情報(顧客名、ケース番号など)を動的に埋め込むための変数(プレースホルダー)を含むことができます。これにより、 Data 360 から取得したデータを基に、文脈に応じた具体的なプロンプトを自動生成し、一貫性と精度の高い応答を実現します。 RAG においては、レトリーバーをプロンプトテンプレートで使用することで、ベクトルデータを用いた動的なグラウンディングが可能になります。
Agentforce
Agentforce は、 Salesforce の各アプリケーション( Sales Cloud, Service Cloud など)で動作する自律型の AI アシスタントです。ユーザーは人間と会話するように自然言語で指示を出すだけで、データの検索、要約、メール作成、アクションの実行など、様々なタスクを自動化できます。また、 RAG を実際に利用するためのインターフェースとしても機能します。
Einstein Trust Layer
Einstein Trust Layer は、 Salesforce の生成 AI 機能と LLM の間に位置する、信頼性と安全性を担保するためのセキュアな AI アーキテクチャです。動的グラウンディング、ゼロデータリテンション、有害性検出などの機能を備え、 Data 360 のデータを RAG で活用する際、この Trust Layer が働くことで、企業の機密データが外部の LLM に保持されたり、情報が意図せず漏洩したりするリスクを防ぎます。これにより、企業はコンプライアンスを遵守しながら、安心して生成 AI を活用することができます。
公開日 : 2025.07.29
Share:
この情報は役に立ちましたか?
ご意見お待ちしております。
フィードバックありがとうございます。
より役に立つために
役に立たなかった一番の理由を教えてください。
活用ステップ
-
STEP1. はじめに
-
STEP2. 概要
-
STEP3. データ取込
-
STEP4. 準備
-
STEP5. 活用
