「検索インデックス」によるベクトルデータベース構築
公開日 : 2025.07.29
Share:



2025 年 10 月 14 日以降、Data Cloud は Data 360 にブランド変更されました。
この記事で学べること
- 検索インデックスの概要
- 検索インデックスの設定の2つの方法とその違い
- 検索インデックス設定のベストプラクティス
- チャンクの強化オプション(Chunk Enrichment)の概要
検索インデックスとは
この記事では、 Data 360 の機能である「検索インデックス」について詳しく説明します。検索インデックスとは何か、その設定によりどのような処理が行われるのかを確認した上で、設定の概要やベストプラクティスも紹介いたします。
- 検索インデックスとは: 構造化/非構造化データを RAG で検索可能にするための Data 360 の機能です。データソースとなるデータモデルオブジェクトを選択して検索インデックスを設定すると、 Data 360 がそのデータを意味のあるかたまりにチャンク化(分割)し、その分割したデータをベクトル化(数値化)して検索可能な状態に処理します。このプロセスがあることで、 Data 360 に取り込んだデータの中からユーザーの質問に意味や文脈が近いデータを検索できるようになります。
- 検索インデックスに関わるデータモデルオブジェクト ( DMO ): Data 360 で検索インデックスを設定すると、データソースのデータモデルオブジェクトに対応する Chunk DMO と Index DMO が自動で作成されます。詳細はこちらのヘルプ記事をご参照ください。
- DMO / UDMO: ソースデータのデータモデルオブジェクト。UDMO は、アップロードファイルのような非構造化データを格納するための Unstructured(非構造化) DMO を意味する。
- Chunk DMO: ソースデータから、意味のまとまりで分割されたチャンクテキストが格納されるデータモデルオブジェクト。 Chunk DMO のデータをグラウンディングに使用することで、プロンプトに文脈のある情報を渡すことができる。
- Index DMO: チャンクテキストをベクトル化(数値化)した値を格納するデータモデルオブジェクト。Chunk オブジェクトのレコードと対になって作成され、検索時はこのベクトルをもとに意味の近いデータが特定される。
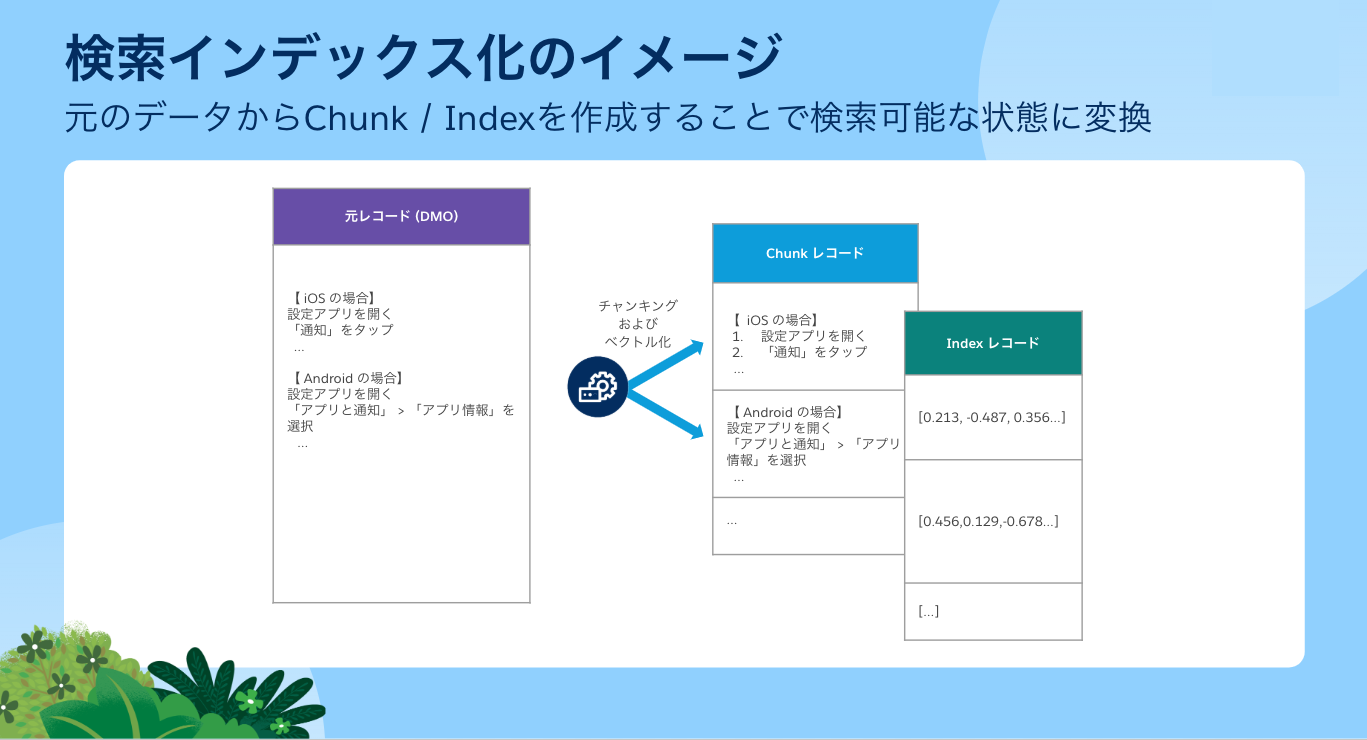
設定の概要
検索インデックスの設定には、主に2つの方法があります。
- Agentforce データライブラリによる作成: Agentforce データライブラリ機能を使用すると、簡単ないくつかのステップだけで自動で検索インデックスの設定を行うことができます。対応データは、 Service Cloud のナレッジオブジェクト、アップロードファイル( PDF, HTML, Text )です。簡単に使い始めることができる点はメリットですが、対応データが限られていることと、設定できる内容に限りがあるため、上記以外のデータソースを扱ったり、より高度な設定が必要な場合は Data 360 で手動で検索インデックスを設定します。
- 検索インデックス作成: Data 360 の「検索インデックス」より、詳細な設定を反映した検索インデックスの設定が可能です。UI上の操作で設定できるためコードは不要です。 Agentforce データライブラリでは対応していないデータも利用できるほか、検索方式、対象データのフィルター条件など、より高度な制御が行えます。

ベストプラクティス
検索インデックスにより RAG の精度を高めるには、有効なデータに対して適切な設定を行うことが重要です。
- コンテキスト(文脈)のある項目やデータを用意する: キーワード単体ではなく、その言葉がどのような意味で使われているかが分かる文章や段落があるデータが検索インデックスの対象として適しています。ユーザーの質問との意味の類似性をより正確に捉え、文脈に沿った的確な回答を生成しやすくなります。
- 最低限の項目を検索インデックスの対象にする: 本文とは無関係な情報(定型文、記事番号など)を排除し、 RAG が参照すべき本質的な情報だけに絞って検索インデックスを設定します。これにより、検索ノイズが減り、精度と効率が向上します。不要なデータを除外することで、プロンプトに誤った情報や不完全な情報を与える可能性を低減させることができます。
チャンクの強化オプション(Enriched Chunks)の概要
「チャンクの強化」は、非構造化データをベクトル化する際、LLM を活用して検索用の付加情報(メタデータ)を自動生成・付与する機能です。
Agentforce 等の AI アプリケーションが、より文脈に即した適切な情報を参照できるようになり、回答の妥当性(精度)の向上が期待できます。
従来の検索インデックスとの違い 従来の「テキストを一定の長さで機械的に分割する」手法に対し、チャンクの強化を有効にすると、Data 360 では以下の 3 種類のチャンクが生成され、RAG や AI エージェントのワークフローで活用されます。
- 元のチャンクテキスト: オリジナルのテキストデータ
- メタデータテキスト: LLM が生成した説明や要約
- 回答可能な質問: そのチャンクから回答可能な想定質問
本機能の利用に伴うクレジット消費(Flex クレジット等)の仕様 や、処理に伴う データ処理リージョン(国外へのデータ送信の可能性)に関する考慮事項は、製品アップデートにより変更される可能性があります。
詳細はこちらのヘルプ記事をご参照ください。
まとめ
検索インデックスとは、指定したデータをチャンク化・ベクトル化し、検索可能な状態にする Data 360 の機能です。検索インデックスを設定することにより、 Agentforce が検索できるデータ基盤が構築されます。 Agentforce データライブラリによる設定と Data 360 における手動設定の 2 つの方法があり、後者の方がより詳細な設定や高度な制御が可能です。 RAG の精度を高めるためには、文脈のあるデータを用意し、検索インデックスの対象を必要最低限の項目に絞ることが重要です。次の記事では、そのデータを検索する役割を担う「レトリーバー」について詳しく解説します。
学習ツール
Premier Success Plan をご契約のお客様は、この記事の内容について 1 対 1 のフォローアップセッションでご相談いただけます。
具体的な設定方法などについてご支援が必要でしたらぜひ以下のリンクよりお申し込みくださいませ。
エキスパートコーチング: Data 360 : AI & Agentforce
参考リソース
公開日 : 2025.07.29
Share:
この情報は役に立ちましたか?
ご意見お待ちしております。
フィードバックありがとうございます。
より役に立つために
役に立たなかった一番の理由を教えてください。
活用ステップ
-
STEP1. はじめに
-
STEP2. 概要
-
STEP3. データ取込
-
STEP4. 準備
-
STEP5. 活用
